Train Kernel Parameters
![]()
You are seeing the HTML output generated by Documenter.jl and Literate.jl from the Julia source file. The corresponding notebook can be viewed in nbviewer.
Here we show a few ways to train (optimize) the kernel (hyper)parameters at the example of kernel-based regression using KernelFunctions.jl. All options are functionally identical, but differ a little in readability, dependencies, and computational cost.
We load KernelFunctions and some other packages. Note that while we use Zygote for automatic differentiation and Flux.optimise for optimization, you should be able to replace them with your favourite autodiff framework or optimizer.
Zygote is not expected to work on Julia ≥ 1.12. Use a different AD package for Julia ≥ 1.12, or use Julia 1.11 to run this example.
using KernelFunctions
using LinearAlgebra
using Distributions
using Plots
using BenchmarkTools
using Flux
using Flux: Optimise
using Zygote
using Random: seed!
seed!(42);Data Generation
We generate a toy dataset in 1 dimension:
xmin, xmax = -3, 3 # Bounds of the data
N = 50 # Number of samples
x_train = rand(Uniform(xmin, xmax), N) # sample the inputs
σ = 0.1
y_train = sinc.(x_train) + randn(N) * σ # evaluate a function and add some noise
x_test = range(xmin - 0.1, xmax + 0.1; length=300)Plot the data
scatter(x_train, y_train; label="data")
plot!(x_test, sinc; label="true function")
Manual Approach
The first option is to rebuild the parametrized kernel from a vector of parameters in each evaluation of the cost function. This is similar to the approach taken in Stheno.jl.
To train the kernel parameters via Zygote.jl, we need to create a function creating a kernel from an array. A simple way to ensure that the kernel parameters are positive is to optimize over the logarithm of the parameters.
function kernel_creator(θ)
return (exp(θ[1]) * SqExponentialKernel() + exp(θ[2]) * Matern32Kernel()) ∘
ScaleTransform(exp(θ[3]))
endFrom theory we know the prediction for a test set x given the kernel parameters and normalization constant:
function f(x, x_train, y_train, θ)
k = kernel_creator(θ[1:3])
return kernelmatrix(k, x, x_train) *
((kernelmatrix(k, x_train) + exp(θ[4]) * I) \ y_train)
endLet's look at our prediction. With starting parameters p0 (picked so we get the right local minimum for demonstration) we get:
p0 = [1.1, 0.1, 0.01, 0.001]
θ = log.(p0)
ŷ = f(x_test, x_train, y_train, θ)
scatter(x_train, y_train; label="data")
plot!(x_test, sinc; label="true function")
plot!(x_test, ŷ; label="prediction")
We define the following loss:
function loss(θ)
ŷ = f(x_train, x_train, y_train, θ)
return norm(y_train - ŷ) + exp(θ[4]) * norm(ŷ)
endThe loss with our starting point:
loss(θ)2.613933959118708Computational cost for one step:
@benchmark let
θ = log.(p0)
opt = Optimise.AdaGrad(0.5)
grads = only((Zygote.gradient(loss, θ)))
Optimise.update!(opt, θ, grads)
endBenchmarkTools.Trial: 3872 samples with 1 evaluation per sample.
Range (min … max): 755.577 μs … 318.918 ms ┊ GC (min … max): 0.00% … 99.60%
Time (median): 844.883 μs ┊ GC (median): 0.00%
Time (mean ± σ): 1.291 ms ± 8.835 ms ┊ GC (mean ± σ): 27.62% ± 13.54%
▃▆██▆▃▁ ▁▃▃▃ ▁
███████▇▆▆▄▆▁▃▄▁▁▃▃▁▃▁▁▃▁▃▁▁▃▁▁▁▁▁▁▁▁▁▃▅██████▇▇▆▆▇█▇▇▆▅▆▅▃▃▅ █
756 μs Histogram: log(frequency) by time 2.44 ms <
Memory estimate: 2.98 MiB, allocs estimate: 1807.Training the model
Setting an initial value and initializing the optimizer:
θ = log.(p0) # Initial vector
opt = Optimise.AdaGrad(0.5)Optimize
anim = Animation()
for i in 1:15
grads = only((Zygote.gradient(loss, θ)))
Optimise.update!(opt, θ, grads)
scatter(
x_train, y_train; lab="data", title="i = $(i), Loss = $(round(loss(θ), digits = 4))"
)
plot!(x_test, sinc; lab="true function")
plot!(x_test, f(x_test, x_train, y_train, θ); lab="Prediction", lw=3.0)
frame(anim)
end
gif(anim, "train-kernel-param.gif"; show_msg=false, fps=15);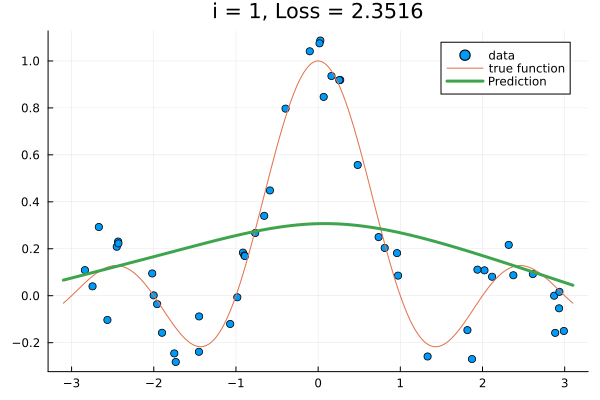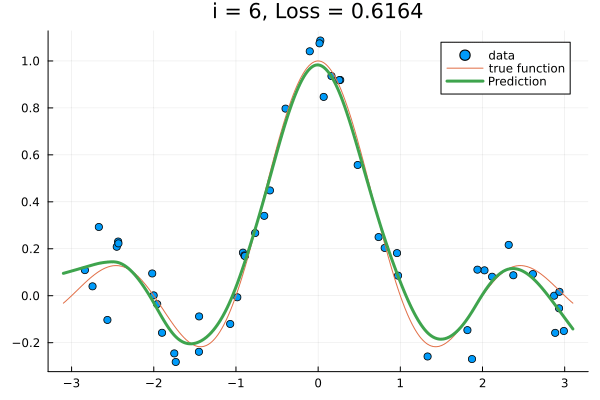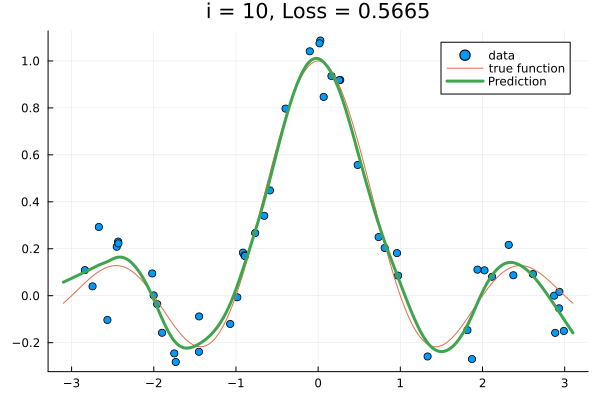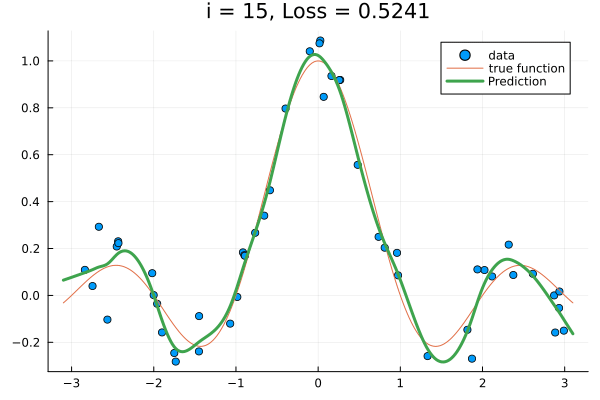
Final loss
loss(θ)0.5241118228076058Using ParameterHandling.jl
Alternatively, we can use the ParameterHandling.jl package to handle the requirement that all kernel parameters should be positive. The package also allows arbitrarily nesting named tuples that make the parameters more human readable, without having to remember their position in a flat vector.
using ParameterHandling
raw_initial_θ = (
k1=positive(1.1), k2=positive(0.1), k3=positive(0.01), noise_var=positive(0.001)
)
flat_θ, unflatten = ParameterHandling.value_flatten(raw_initial_θ)4-element Vector{Float64}:
0.09531016625781467
-2.3025852420056685
-4.6051716761053205
-6.907770180254354We define a few relevant functions and note that compared to the previous kernel_creator function, we do not need explicit exps.
function kernel_creator(θ)
return (θ.k1 * SqExponentialKernel() + θ.k2 * Matern32Kernel()) ∘ ScaleTransform(θ.k3)
end
function f(x, x_train, y_train, θ)
k = kernel_creator(θ)
return kernelmatrix(k, x, x_train) *
((kernelmatrix(k, x_train) + θ.noise_var * I) \ y_train)
end
function loss(θ)
ŷ = f(x_train, x_train, y_train, θ)
return norm(y_train - ŷ) + θ.noise_var * norm(ŷ)
end
initial_θ = ParameterHandling.value(raw_initial_θ)The loss at the initial parameter values:
(loss ∘ unflatten)(flat_θ)2.613933959118708Cost per step
@benchmark let
θ = flat_θ[:]
opt = Optimise.AdaGrad(0.5)
grads = (Zygote.gradient(loss ∘ unflatten, θ))[1]
Optimise.update!(opt, θ, grads)
endBenchmarkTools.Trial: 3318 samples with 1 evaluation per sample.
Range (min … max): 903.732 μs … 326.022 ms ┊ GC (min … max): 0.00% … 99.59%
Time (median): 996.615 μs ┊ GC (median): 0.00%
Time (mean ± σ): 1.506 ms ± 9.768 ms ┊ GC (mean ± σ): 28.25% ± 13.99%
▁▅█▇▅▂ ▃▃ ▁
██████▇▇▄▅▆▆▁▁▅▁▅▃▁▁▁▄▁▃▁▁▁▁▁▁▁▁▁▁▁▁▅███▇▅▅▅▅▇▆▆▆▇▇▇▇▇▇▆▆▆▅▃▅ █
904 μs Histogram: log(frequency) by time 2.77 ms <
Memory estimate: 3.07 MiB, allocs estimate: 2507.Training the model
Optimize
opt = Optimise.AdaGrad(0.5)
for i in 1:15
grads = (Zygote.gradient(loss ∘ unflatten, flat_θ))[1]
Optimise.update!(opt, flat_θ, grads)
endFinal loss
(loss ∘ unflatten)(flat_θ)0.524117624126251Flux.destructure
If we don't want to write an explicit function to construct the kernel, we can alternatively use the Flux.destructure function. Again, we need to ensure that the parameters are positive. Note that the exp function is now part of the loss function, instead of part of the kernel construction.
We could also use ParameterHandling.jl here. To do so, one would remove the exps from the loss function below and call loss ∘ unflatten as above.
θ = [1.1, 0.1, 0.01, 0.001]
kernel = (θ[1] * SqExponentialKernel() + θ[2] * Matern32Kernel()) ∘ ScaleTransform(θ[3])
params, kernelc = Flux.destructure(kernel);This returns the trainable params of the kernel and a function to reconstruct the kernel.
kernelc(params)Sum of 2 kernels:
Squared Exponential Kernel (metric = Distances.Euclidean(0.0))
- σ² = 1.1
Matern 3/2 Kernel (metric = Distances.Euclidean(0.0))
- σ² = 0.1
- Scale Transform (s = 0.01)From theory we know the prediction for a test set x given the kernel parameters and normalization constant
function f(x, x_train, y_train, θ)
k = kernelc(θ[1:3])
return kernelmatrix(k, x, x_train) * ((kernelmatrix(k, x_train) + (θ[4]) * I) \ y_train)
end
function loss(θ)
ŷ = f(x_train, x_train, y_train, exp.(θ))
return norm(y_train - ŷ) + exp(θ[4]) * norm(ŷ)
endCost for one step
@benchmark let θt = θ[:], optt = Optimise.AdaGrad(0.5)
grads = only((Zygote.gradient(loss, θt)))
Optimise.update!(optt, θt, grads)
endBenchmarkTools.Trial: 3780 samples with 1 evaluation per sample.
Range (min … max): 745.608 μs … 340.067 ms ┊ GC (min … max): 0.00% … 99.65%
Time (median): 843.755 μs ┊ GC (median): 0.00%
Time (mean ± σ): 1.322 ms ± 9.534 ms ┊ GC (mean ± σ): 30.14% ± 14.73%
▂▄██▅▃▁ ▁▃▂ ▁
███████▇▅▅▅▄▃▁▃▄▁▄▁▃▄▁▃▁▃▃▁▁▁▁▁▁▁▁▃▆████▆▅▃▁▁▄▄▅▆▇████▇▇▇▇▆▅▆ █
746 μs Histogram: log(frequency) by time 2.66 ms <
Memory estimate: 2.98 MiB, allocs estimate: 1806.Training the model
The loss at our initial parameter values:
θ = log.([1.1, 0.1, 0.01, 0.001]) # Initial vector
loss(θ)2.613933959118708Initialize optimizer
opt = Optimise.AdaGrad(0.5)Optimize
for i in 1:15
grads = only((Zygote.gradient(loss, θ)))
Optimise.update!(opt, θ, grads)
endFinal loss
loss(θ)0.5241118228076058Package and system information
Package information (click to expand)
Status `~/work/KernelFunctions.jl/KernelFunctions.jl/examples/train-kernel-parameters/Project.toml` [6e4b80f9] BenchmarkTools v1.8.0 [31c24e10] Distributions v0.25.129 ⌅ [587475ba] Flux v0.14.25 ⌅ [f6369f11] ForwardDiff v0.10.39 [ec8451be] KernelFunctions v0.11.0 `/home/runner/work/KernelFunctions.jl/KernelFunctions.jl#master` [98b081ad] Literate v2.21.0 ⌅ [2412ca09] ParameterHandling v0.4.10 [91a5bcdd] Plots v1.41.6 ⌅ [e88e6eb3] Zygote v0.6.77 [37e2e46d] LinearAlgebra v1.12.0 Info Packages marked with ⌅ have new versions available but compatibility constraints restrict them from upgrading. To see why use `status --outdated`To reproduce this notebook's package environment, you can download the full Manifest.toml.
System information (click to expand)
Julia Version 1.12.6 Commit 15346901f00 (2026-04-09 19:20 UTC) Build Info: Official https://julialang.org release Platform Info: OS: Linux (x86_64-linux-gnu) CPU: 4 × AMD EPYC 7763 64-Core Processor WORD_SIZE: 64 LLVM: libLLVM-18.1.7 (ORCJIT, znver3) GC: Built with stock GC Threads: 1 default, 1 interactive, 1 GC (on 4 virtual cores) Environment: JULIA_LOAD_PATH = :/home/runner/.julia/packages/JuliaGPsDocs/7M86H/src
This page was generated using Literate.jl.